Live & Listening !
Mendix and OutSystems: To Choose Between Two Low-Code Industry Heavyweights
The solution is meant for the Customer that have vast geographical expanse and operational diversity, facing challenges in standardizing and managing external customer complaints. This study explores the design and implementation of a comprehensive web system leveraging Microsoft’s Power Platform and SharePoint Online.
The goal is to streamline complaint registration, ensure timely response, provide global oversight, and automate reporting functionalities.
Hayley, a seasoned data analyst, is running a complex query that has been spinning against her company’s massive data warehouse for what seems like forever. She faces a deadline, and the loop traps all the insights her leadership requires to make critical decisions.
This scenario is a common one for analysts and businesses navigating growing volumes of data in situations where every piece of insight matters. The problem behind these dead ends and delayed insights could very well be the structure of your data warehouse and how efficient or inefficient it is at extracting insights.
In this article, we will explore the two prevalent schema types, Star and Snowflake, and present a case showcasing how each schema contributes to noteworthy performance optimizations.
The Critical Role of Data Warehousing Schemas
The simplest way to explain this is to compare a data warehouse with a library and think of how those vast amounts of information in a well-stocked library would prove useless without a well-functioning catalog system that helps anyone walking into the building find the book they need. The library is your data warehouse, the catalog system is the schema, and the book is the specific data you need.
In data warehousing, choosing the right schema is a strategic technical decision.
- Schema defines how data is stored, organized, and retrieved.
- Bridges the gap between complex raw data and action-friendly insights and visual reports.
- Ensures accessible data, efficient query runs, and quick and accurate insights.
Without an efficient schema in place, a host of problems arise.
- Scattered data results in slow queries where even simple results could get lost in a cascade of joins and calculations.
- Redundancy is a possible data hazard too, with data duplication that bloats the database and derails performance.
Your choice of schema impacts efficiency, performance, and the very value you can derive from your hard-earned data.
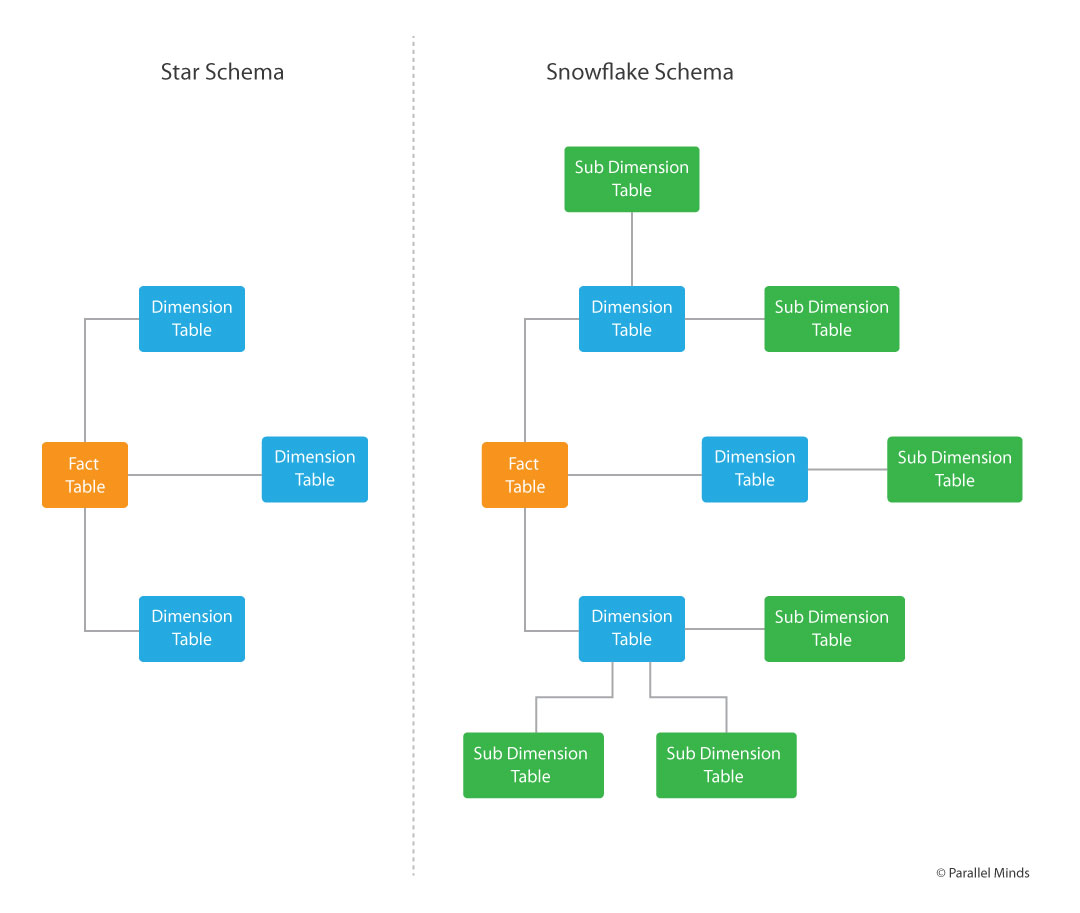
Understanding Star Schema
Key Characteristics of Star Schema
- A central fact table holds the measurable or quantitative data.
- Dimension tables provide the descriptions or context for these facts.
- The intentional denormalization of dimension tables, i.e., redundant data, to simplify queries.
- Simple relationships between the fact table and dimension tables accommodate straightforward queries and simple understandings.
Strengths of Star Schema
- The simple structure of star schema means it is easy to design, implement, and understand, enabling even non-technical users to get on board and write basic queries.
- Denormalized queries mean fewer joins and, therefore, quicker query executions. In dashboards where speed is crucial, star schema structures deliver great results.
- When the relationship between facts and dimensions is clear and simple, a star schema data model works efficiently.
Weaknesses of Star Schema
- Denormalized dimension tables lead to data redundancy, and this duplication increases storage costs, particularly for large data warehouses.
- Updating data in a denormalized dimension table requires changes across multiple rows, which is confusing, time-consuming, and error-prone.
- The simplicity of the star schema prevents it from supporting complex and nuanced analytical queries that require granular relationships with dimension tables.
So, while Star Schema’s simple structure is a great starting point for data warehouses, as volumes grow and analytical needs grow more complex, it falls short due to inflexibility and data redundancy.
Understanding Snowflake Schema
Weaknesses of Star Schema
- The fact table serves as the core and stores the relevant quantitative measurements or metrics.
- As a key difference, the dimension tables in this schema are normalized and broken down into multiple related tables.
- Normalization leads to a parent-child relationship between tables with the creation of a hierarchical structure within dimensions.
- The normalization process assists in complex relationships between the fact table and dimension tables, and even within the dimension tables.
Strengths of Snowflake Schema
- The elimination of redundant data means large data warehouses now spend significantly less on storage, a financial advantage for data-intensive businesses.
- Normalization leads to easy updates and modifications, where only one place requires changes that are then reflected across the structure.
- Granular relationships support complex queries and ad hoc analysis, a feature that is valuable in industries where in-depth analysis is crucial for optimization and decision-making.
Weaknesses of Snowflake Schema
- Normalization leads to complex queries that require multiple joins, a scenario that can be challenging for users unaccustomed to complex query designs.
- Slower query performance is a risk associated with normalization, and only elaborate optimization solutions like materialized views and strategic indexing can resolve this.
- The design and implementation of this schema are fairly challenging due to its complexities and require a thorough understanding of the data model and its relationships.
Focused on normalization and data integrity, the Snowflake Schema offers advantages in efficiency and analytic abilities. Query complexities and the resultant impact on performance, however, are factors to consider.
Choosing the Right Schema for Your Business
Bringing to data warehousing processes unique sets of advantages, both Star and Snowflake schemas align with specific data and analytical needs, offering performance, speed, and complex abilities on different levels.
Star Schema: Simplicity+Speed
- A denormalized structure without the need for complex joins; delivers simpler, quicker results.
- Indexing and partitioning to improve query performance for frequently accessed data.
- Prioritizing ease of use to empower non-technical users by optimizing smaller data volumes.
Snowflake Schema: Storage Efficiency+Flexibility
- Storage savings for cloud-based environments and large data warehouses.
- Tier management for “hot” and “cold” data.
- Materialized views and efficient handling of complex hierarchical data structures.
At Parallel Minds, we leverage the advantages of each schema and optimize them to deliver maximum efficiency based on your unique organizational needs.
Partnering with Parallel Minds
At Parallel Minds, we understand just how crucial the decision to choose the right schema is for a business. Our Data Engineers and Scientists are committed to helping you extract maximum value from your data in the most efficient and cost-effective way possible.
Get in touch to learn how the Parallel Minds team can help you introduce performance optimization to your data warehousing journey.